RESEARCH
ゲノムや言語をどう読み解くか?
言語とゲノムの意外な関係
─かな漢字変換と遺伝子発見
「かな漢字変換プログラム」と「遺伝子発見プログラム」は実はほとんど同じソフトウェアである。薮から棒に、こいつは一体何を言い出すんだと思われたかもしれないが、そんなことでもなければ、言語処理を専門とする電話会社の研究者が生命科学の雑誌に登場するわけがない。
例えて言えば、幼い頃に別離し、全く別の境遇で育った兄弟が、数奇な巡り合わせから再会し、お互いにあまりにも良く似ているので驚く。実はこの二人は異母兄弟で、兄である「かな漢字変換」の母親は「言語処理」、弟の「遺伝子発見」の母親は「ゲノム解析」、そして、二人の共通の父親は「隠れマルコフモデル」である。この父親はなかなか隅に置けない奴で、「音声認識」という女性とも深い仲にあるのだが、その件については話が複雑になるのでここでは触れない。
我々が日本語の文書を読む場合、無意識のうちに内容を理解してしまうので、言語とゲノムはとても同じものとは思えないかもしれない。しかし、もしそれが、ハングルやアラビア文字で書かれていたらどうだろう? どこからどこまでが一つの単語なのか、いや、どこからどこまでが一つの文字なのかさえ判別できないに違いない。
コンピュータにとっては、日本語も韓国語もヒトゲノムも、ただの記号列に過ぎない。約100種類のひらがなで構成された文字列から単語を発見する「かな漢字変換」と、4種類の塩基の配列であるゲノムから遺伝子を発見する問題は、基本的には同じなのである。
コンピュータで言語を解析するとはどういうことかを実感してもらうために、漢字表記の日本語文字列から単語を発見する問題を考えてみよう。
例えば、「畜産物価格安定法」は、「畜産物」「価格」「安定法」という単語列から構成される複合名詞であることを、我々は容易に認識できる。ところがコンピュータにはこれが難しい。
図1に示すように、「畜産」「産物」「物価」「価格」「格安」「安定」「定法」など、すべての隣接した2文字の漢字列がすべて語を形成するだけでなく、「産」「物」「価」「格」「安」「定」「法」などほとんどの漢字が一文字でも語を形成する。そのため、「畜産|物価|格安|定法」「畜産|物価|格|安定|法」など非常に多くの単語分割の可能性が存在するのである。
<図1>
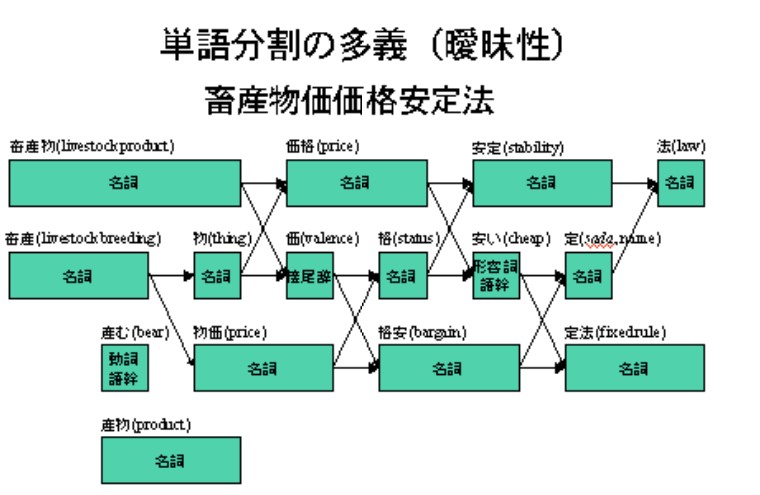
例えば、「畜産物価格安定法」は、「畜産物」「価格」「安定法」という単語列から構成される複合名詞であることを、我々は容易に認識できる。ところがコンピュータにはこれが難しい。
図1に示すように、「畜産」「産物」「物価」「価格」「格安」「安定」「定法」など、すべての隣接した2文字の漢字列がすべて語を形成するだけでなく、「産」「物」「価」「格」「安」「定」「法」などほとんどの漢字が一文字でも語を形成する。そのため、「畜産|物価|格安|定法」「畜産|物価|格|安定|法」など非常に多くの単語分割の可能性が存在するのである。
同様の問題は、ひらがな表記された文字列を漢字かな混じり表記に変換する「かな漢字変換」でも発生する。例えば、「へんなじがでる」をかな漢字変換する場合を考えると、これも色々な解釈が可能である。
へんな/形容詞 じが/名詞 でる/動詞 → 変な自我出る, 変な自画出る ,..
へんな/形容詞 じ/名詞 が/助詞 でる/動詞 → 変な字が出る, 変な痔が出る, ...
かな漢字変換プログラムの仕事は、(1)ひらがなで表記された入力文を単語に分割し、(2)それぞれの単語の可能な漢字表記(同音異義語)の中で最も妥当なものを選ぶ、という2つである。(1)に失敗すると「変な自我出る」になり、(2)に失敗すると「変な痔が出る」になる。どちらもあり得ないとは言い切れない解釈であるが、かな漢字変換の第1候補として適切とは思えない。
かな漢字変換で正解を得る鍵は、複数の解釈の可能性の中から日本語として最も妥当な解釈を選択するための判断基準、すなわち、日本語の「文法」をコンピュータ上で表現する方法にある。1980年代の初期のパソコンやワープロに付属したかな漢字変換は、上記の例のような珍答・迷答のオンパレードだったが、最近のかな漢字変換は随分と「賢く」なっている。その背景にあるのが「隠れマルコフモデル」である。
少し難しい話になるが、一般に、ある記号の出現確率が直前の記号のみに依存すると仮定する確率モデルを「マルコフモデル」という。これに対して、マルコフ過程に従って遷移する内部状態、および、各状態における記号の出現確率分布から構成される確率モデルを「隠れマルコフモデル」という。外部から観測できるのは記号の系列だけであり、内部の状態遷移は直接観測できないところから「隠れ」マルコフと呼ばれる。
名詞・動詞などの品詞を内部状態と考え、単語を外部から観測できる記号と考えると、言語の生成過程は隠れマルコフモデルで近似できる。隠れマルコフモデルで日本語の「文法」を表現した例を図2に示す。図2では、グラフの節点が内部状態(品詞)を表し、節点間の矢印が状態遷移およびその確率を表す。節点に付属するテーブルは状態別の記号(単語)の出現確率である。
<図2>
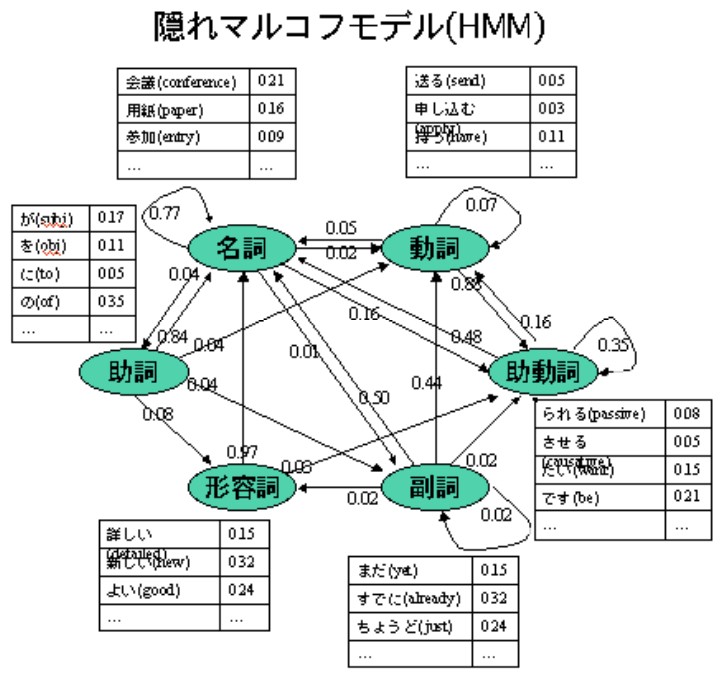
「へんなじがでる」のかな漢字変換において、「変な自我出る」を不自然と感じる主な原因は、「自我」という名詞の直後に「出る」という動詞が接続し、助詞が省略されているせいである。標準的な日本語では、名詞の直後には動詞より助詞が接続する可能性が高い。隠れマルコフモデルでは、このような単語の接続の自然性を状態遷移確率の大小で表現する。また、「じ」の変換候補としては「痔」より「字」の方が可能性が高いことは、名詞という内部状態における出現確率の大小で表現する。
近年のかな漢字変換が「賢く」なったのは、この隠れマルコフモデルのパラメタ(品詞遷移確率と単語出現確率)を大量のテキストから統計的な手法を使って正確に求められるようになったお陰である。
さて、ゲノムの場合、図2において、文字を塩基(A,T,G,C)、単語をコドン(1つのアミノ酸に対応する3つの塩基)に置き換えれば、やはり隠れマルコフモデルで表現できる。言語における品詞に相当するような、分かりやすい内部状態はまだ解明されていないが、開始コドン(ATGなど)と停止コドン(TAA,TAG,TGA)という内部状態が存在することは良く知られている。
かな漢字変換は、文字列の先頭から末尾までに対応する内部状態遷移の可能性の中で、日本語らしさを表す確率が最も高いものを求める問題であるのに対して、遺伝子発見は、開始コドンから停止コドンまでの内部状態遷移の可能性の中で、遺伝子らしさを表す確率が最も高いものを求める問題である。
実際には、真核生物のゲノムの場合、タンパク質の情報を持つエキソンと何も情報を持たないイントロンが交互に出現するので問題はさらに複雑である。しかし、イントロンとエキソンの間の状態遷移も隠れマルコフで表現することが可能である。
どうだろう? 「かな漢字変換」と「遺伝子発見」が兄弟のように良く似ているという意味を理解して頂けただろうか?
このように、言語解析とゲノム解析は、意外に関係が深い。最近では、アミノ酸配列からタンパク質の立体構造を予測する問題に、言語処理における構文解析の技術を適用できることが分かってきた。今後、一見、無関係なこの二つの分野の交流が進み、さらに新しい技術が生まれることを大いに期待したい。
1.マルコフモデルとは
単語列![]() の同時確率
の同時確率![]() は、一般性を失うことなく、次の条件付き確率の積に分解できる。
は、一般性を失うことなく、次の条件付き確率の積に分解できる。
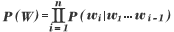
さまざまな単語の組合わせに対して条件付き確率![]() を推定することは現実的に不可能なので、これを
を推定することは現実的に不可能なので、これを![]() 重マルコフ過程で近似したモデルを単語n-gram モデルという。[一般に、ある事象の確率がその直前のN個の事象だけに依存するとき、これをN重マルコフ過程という。]
重マルコフ過程で近似したモデルを単語n-gram モデルという。[一般に、ある事象の確率がその直前のN個の事象だけに依存するとき、これをN重マルコフ過程という。]
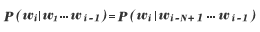
右辺の単語n-gram 確率は、人手により単語分割された訓練テキストがあれば、そのテキスト中の単語列の相対頻度から推定できる。一般に、![]() の値が大きいほど、訓練テキストから信頼性の高い単語n-gram 確率を推定するのが難しくなるので、実際には
の値が大きいほど、訓練テキストから信頼性の高い単語n-gram 確率を推定するのが難しくなるので、実際には![]() または
または![]() とすることが多い。通常、
とすることが多い。通常、![]() の場合を、それぞれ、unigram, bigram, trigram を呼ぶ。
の場合を、それぞれ、unigram, bigram, trigram を呼ぶ。
例えば、単語bigram モデルは以下の式で表される 。
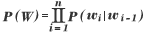
右辺の単語bigram 確率は以下の式により求められる。
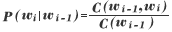
ここで、![]() は単語列の出現頻度を表す。
は単語列の出現頻度を表す。
2.隠れマルコフモデルとは
隠れマルコフモデルは、観測不可能な(隠れた)マルコフ過程と、その状態に依存するシンボル生成器の組合せによって、シンボルの系列を表現するモデルである。
隠れマルコフモデルを言語モデルとして使用する場合、単語列![]() を観測可能なシンボル系列、品詞列
を観測可能なシンボル系列、品詞列![]() を観測不可能な状態系列と考え、
を観測不可能な状態系列と考え、![]() を品詞bigram 確率
を品詞bigram 確率![]() と品詞別単語出現確率
と品詞別単語出現確率![]() の積で近似する。
の積で近似する。
隠れマルコフモデルのパラメータは、人手により単語分割と品詞付与が行われたテキストがあれば、対応する事象の相対頻度から推定できる。
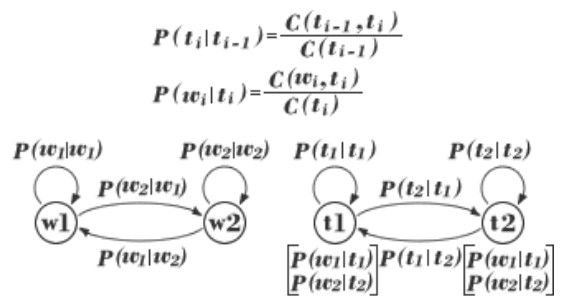
マルコフモデル(左側)と隠れマルコフモデル(右側)
簡単な例として上図に二つの単語![]() から構成されるマルコフモデル、及び、二つの状態(品詞)
から構成されるマルコフモデル、及び、二つの状態(品詞)![]() と二つの単語
と二つの単語![]() から構成される隠れマルコフモデルの例を示す。マルコフモデルは単語を状態と考え、単語間の接続関係を遷移確率として表現するのに対して、隠れマルコフモデルは品詞間の遷移確率により単語間の接続関係を間接的に表現することがわかる。
から構成される隠れマルコフモデルの例を示す。マルコフモデルは単語を状態と考え、単語間の接続関係を遷移確率として表現するのに対して、隠れマルコフモデルは品詞間の遷移確率により単語間の接続関係を間接的に表現することがわかる。
3.その他の方法
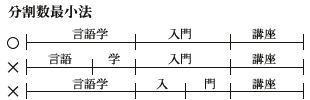
分割数最小法
「言語学入門講座」という文字列を分割数最小法により単語分割する例を下図に示す。この文字列も「言語」、「語学」、「学」、「入」、「門」などが語を形成しうるのでさまざまな単語分割の可能性がある。分割数最小法の場合には、全ての可能な単語分割パターンの中で単語数が最小なものを求める。したがって、「言語学│入門│講座」が3単語なのに対し、「言語│学│入門│講座」や「言語学│入│門│講座」は4単語なので、前者の解釈が優先される。
最長一致法
「畜産物価格安定法」という文字列を最長一致法により単語分割する例を下図に示す。最長一致法では、まず文字列の先頭において「畜産物」と「畜産」という二つの単語のうち、より長い単語である「畜産物」を選ぶ。次ぎに、「畜産物」に続く単語としては「価格」と「価」があるが、より長い単語である「価格」を選ぶ。その後は、「安定」「法」が順に選ばれ、「畜産物│価格│安定│法」という単語分割が得られる。
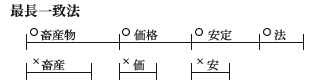
.jpg)
.jpg)