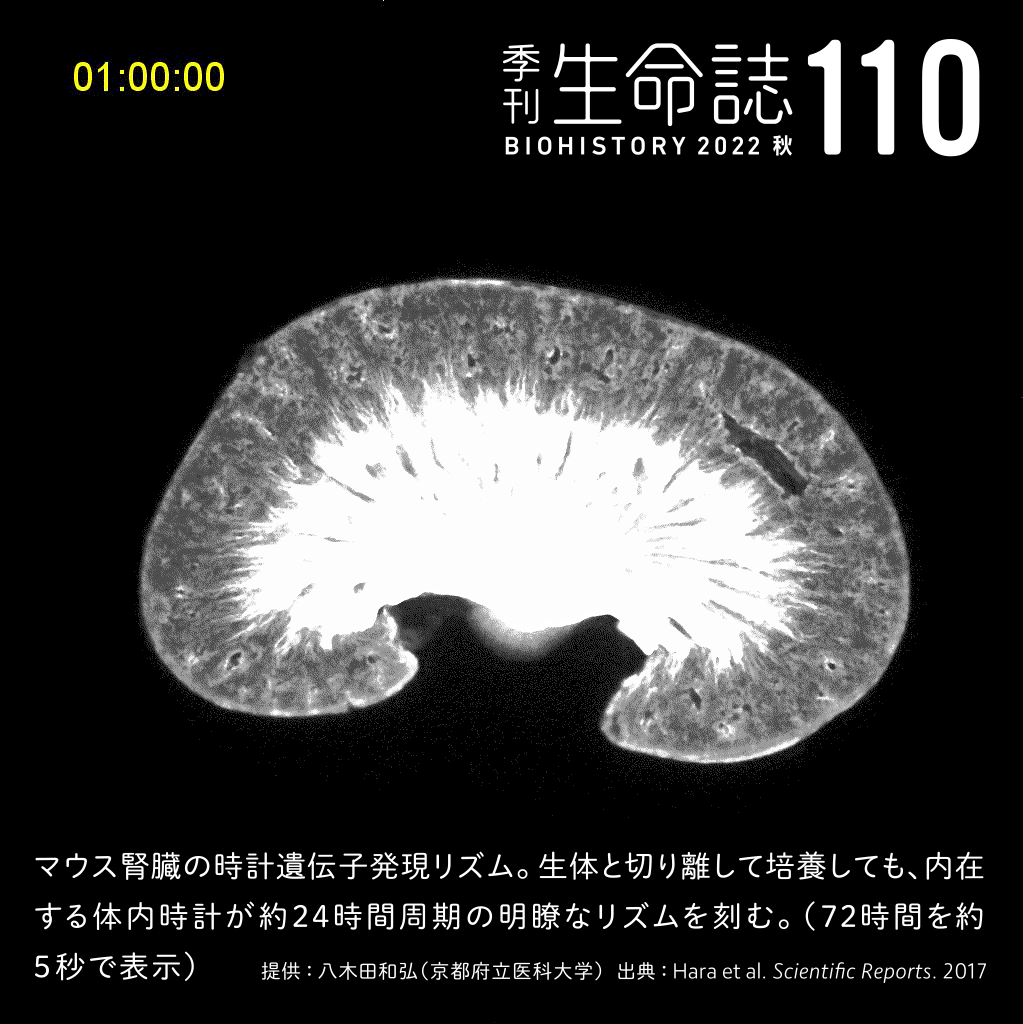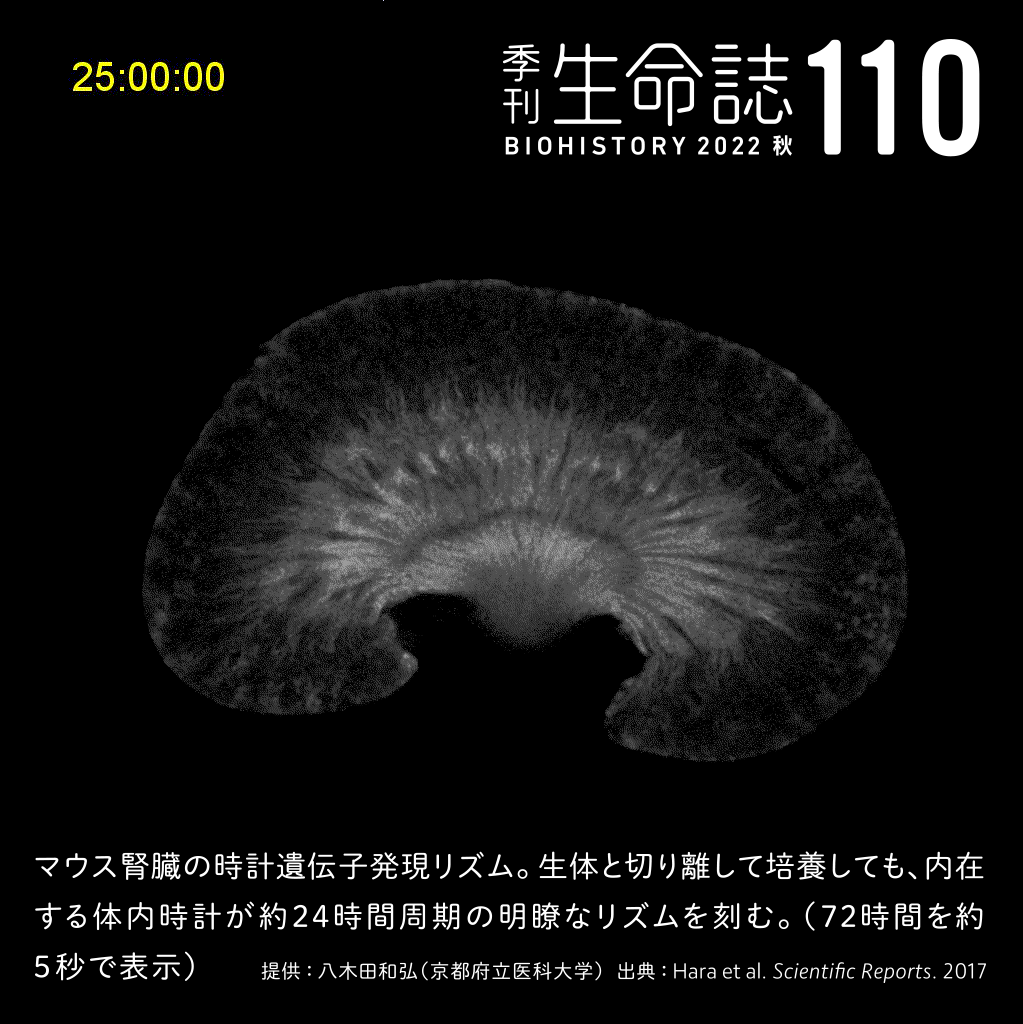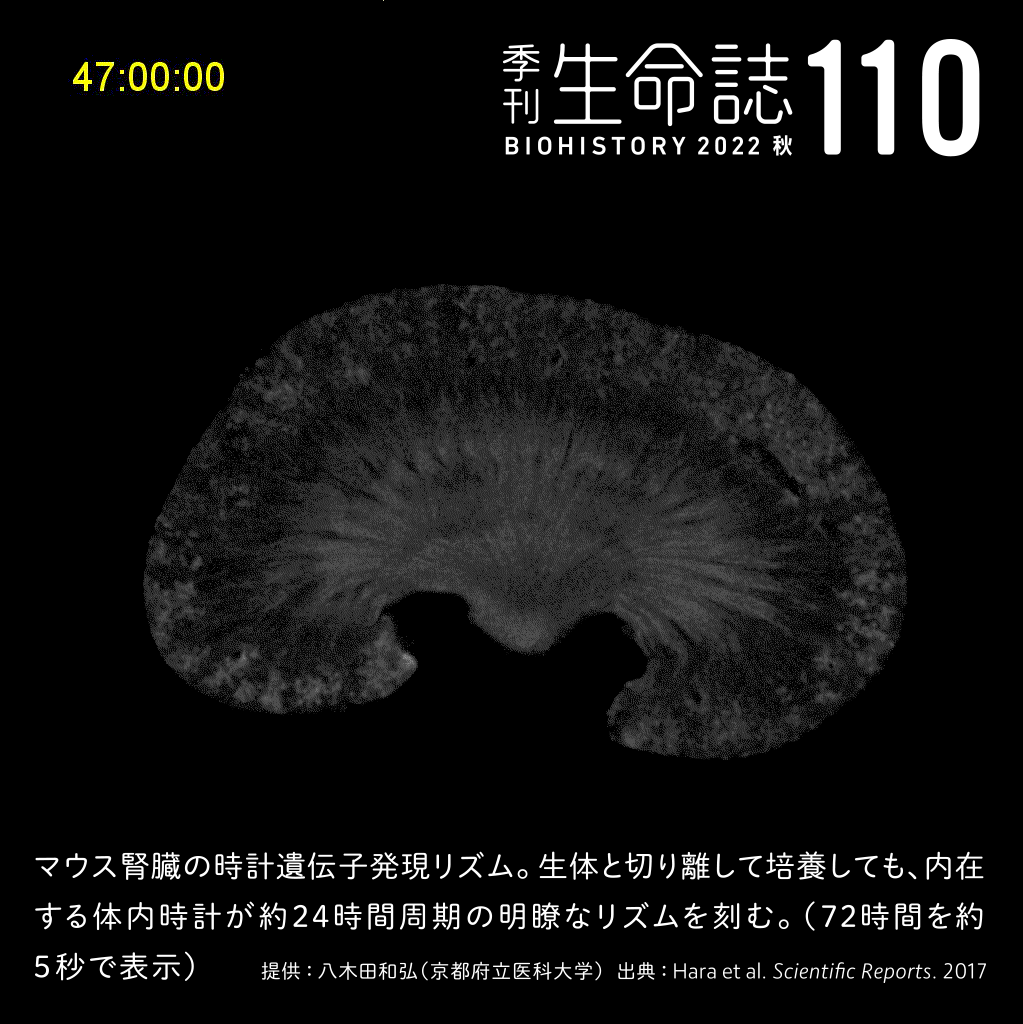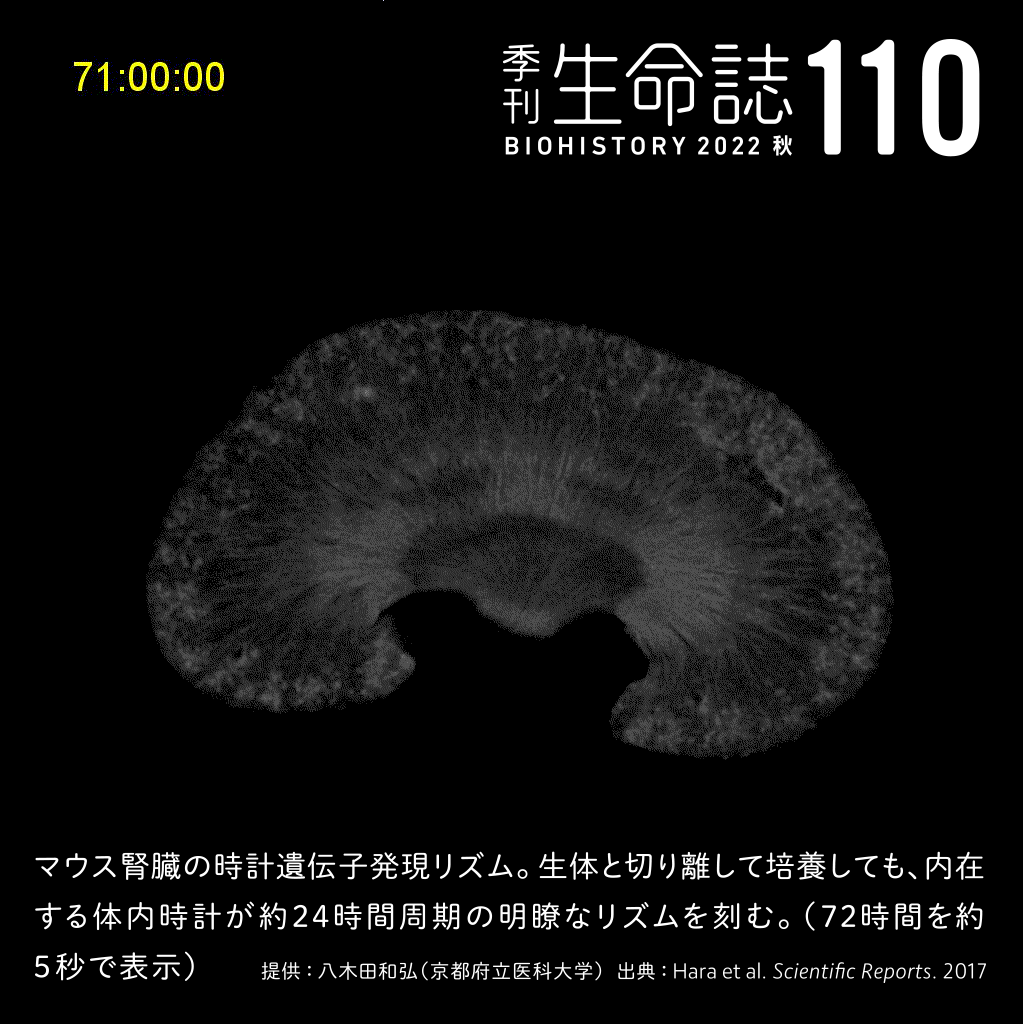
TALK
細胞という知能を理解したいと
1.鉄腕アトムを夢見て
中村
私が生命誌研究館を構想した1985年頃、海外で、細胞に入ったDNAのすべてをゲノムとして捉えようという動きが出ていました。分子生物学は、遺伝子一つひとつのはたらきを追いかけて知見を積み上げてきましたが、これからゲノム解読が始まって大量のデータが出てくる時代になれば、そこから重要な情報を引き出すにはコンピュータの力が必要になるだろうという考え方が少しずつ出ていました。
その中で研究館の活動を始め、館内での研究を進めながら、さまざまな分野の動向を見渡した時に、なんだか面白そうなお仕事を始めた元気な若い人がいらしたんです。一人が冨田さんでもう一人はソニーの北野さん(註1)でした。お二人ともコンピュータの専門家だけれど、どうも生物に関心をもって新しい研究を始めようとしているらしい。私はコンピュータ音痴ですが、是非、いろいろ教えていただきたいと思って、二人を訪ねたのです。
冨田
中村先生に慶応湘南キャンパスまでお越しいただいたのは、E-CELLの形が見えた1999年頃でしたね。
中村
 コンピュータ内に再現した代謝する細胞、つまりE-CELLを見せていただき、初めての体験でしたから楽しかったです。でも、その時の冨田さんは、生物そのものより生命システムへの関心が強いんだと感じ、実験生物学の面白さをいろいろ話したのを思い出します。今では、コンピュータと実験生物学をつなぐ独自の道を切り開いていらして、わくわくします。
コンピュータ内に再現した代謝する細胞、つまりE-CELLを見せていただき、初めての体験でしたから楽しかったです。でも、その時の冨田さんは、生物そのものより生命システムへの関心が強いんだと感じ、実験生物学の面白さをいろいろ話したのを思い出します。今では、コンピュータと実験生物学をつなぐ独自の道を切り開いていらして、わくわくします。
先日、細胞の代謝を丸ごと解析するメタボローム研究をずいぶん広く展開なさっている話を伺い、とても面白かったので生命誌と関連させながら話していただきたいと思いました。
冨田
ありがとうございます。僕の専門は情報科学でした。絶対に、鉄腕アトムみたいなロボットを作ってやるんだという夢を抱いて、意気揚々と米国へ渡ったのが1981年でした。もともとコンピュータで人間の知能を再現する人工知能に興味があり、カーネギーメロン大学の大学院で自動翻訳の研究をしました。今では、英語を日本語に翻訳するソフトも普及していますが、当時はまだ何もなく、その研究をしていたのです。
実は翻訳って、人間の知能をシミュレートするのでかなり奥が深いんですよ。単なる直訳なら辞書と文法のルールをコンピュータに持たせてプログラムを組めばすぐにできますが、それでは良い文章になりません。翻訳は、まず文章を読んで意味を理解し、次にその内容を外国語で作文する、という作業なんですね。そして、文章の意味を理解するためには、世の中の一般常識を知っていなければなりません。
中村
なるほど。私たちは、ふだんあまり意識せずに、かなり複雑なことをやっているわけですね。
冨田
ある文字列から別の文字列に変換する、翻訳という比較的単純な作業ですら、ヒトの脳と同程度の知識や知能を持たなくてはできないわけです。人工知能という学問分野は、画像処理や音声認識などの要素技術については、かなり実用化されて来てはいますが、人間の知能を再現するという究極の目標にはほとんど近づけていませんね。
人間のように主体的にものごとを考え自主的に判断する、本当の意味での「人工知能」はいつになったら実現するだろうかと、当時の若手の人工知能研究者はよく話し合ったものでした。すると皆、あと100年、気の早い人でも50年、中には永久に無理じゃないかと言う人もいましたね。自分が生きている間に実現しそうもないと呆然としていた頃、1989年だったと思いますが、ある日の新聞で、ヒトゲノム計画という見出しに眼が止まったのです。約30億文字というヒトの全プログラムを解読するとてつもないプロジェクトに世界中が協力して取り組むというのです。僕が最初に読んだその記事には、2015年の解読を目指すとありました。
中村
その頃に立てた目標はそうでしたね。それも、考えに考えた末の、希望的観測に基づく目標設定でした。
冨田
 でも僕はそれを読んで、2015年ならまだ自分は現役だと考えた。そして自分は言語処理が専門だからコンピュータで文字列を読むのは得意なわけです。その時、生涯を掛けて取り組むべきは、A,T,G,Cという文字列からなるゲノム、つまり生命の設計図の解明だと確信しました。
でも僕はそれを読んで、2015年ならまだ自分は現役だと考えた。そして自分は言語処理が専門だからコンピュータで文字列を読むのは得意なわけです。その時、生涯を掛けて取り組むべきは、A,T,G,Cという文字列からなるゲノム、つまり生命の設計図の解明だと確信しました。
考えてみれば、今、この瞬間にも地球上のいたるところでヒトという複雑な知的システムが半自動的に生まれている。これは驚くべきことです。この現実を見ずに100年かけて一から人工の知的システムを構築しよう、という発想はどこか間違っていると感じたのです。
ヒトという60兆個の細胞からなるシステムは、最初はたった一つの細胞で、これが分裂をくり返し、互いに情報交換しながら役割分担して、やがて心臓、肝臓、脳などの組織、器官となり、全体として知的に振る舞う。その全プログラムが受精卵のゲノムDNAに書かれており、しかもその情報量はヒトでたった30億文字と聞いて驚きましたよ。人工知能研究者が総力をあげても不可能な超知的システムの作り方がCD1枚に収まってしまう。そう思ってとても興奮しました。当然、生命システムって一体どうなっているのか知りたくなります。僕は、この時、始めて本気で生物学を勉強しようと思いました。
(註1) 北野宏明
【きたの・ひろあき】
1961年生まれ。ソニーコンピュータサイエンス研究所所長。工学博士。著書に『したたかな生命』など。
関連記事:生命誌ジャーナル16号「コンピュータでつくる生物モデル」
2.複雑で多様で例外だらけ
中村
生物学者は実は当時の解析技術のことを考えて無理かもしれないと思っている人が多かったのです。外からの期待のほうが大きかった。冨田さんにとってはよい出会いでしたね。
冨田
学生時代は暗記科目の生物学が嫌いでした。小学校の頃、「アブラナの雌しべは何本でしょう」という問題を出されて、どうしてそれを憶える必要があるのかわからなかった。図鑑を見ればいいじゃないって(笑)。
それで好きなコンピュータにのめり込んだんです。その先で、生物学をやることになるとは思いもしませんでした。ゲノムを知って生物学を勉強したいと思った時、僕は、アメリカで准教授として人工知能の授業を教えていました。幸いカーネギーメロン大学には、教員が他学部の授業を履修することを推奨する制度があり、早速、それを活用してBiology Departmentの大学一年生向けの授業 “ Introduction to Modern Biology ” を受講しました。その最初の授業で、担当の若い先生が、「生物学の教師には二通りある」とおっしゃったんです。一つは、「生物は複雑で多様で例外だらけ」という見方の人、もう一つは、「生物は複雑で多様で例外だらけのように見えるけれども基本的なところは共通だ」という見方の人だと。先生自身は二つ目の方で、まさに大腸菌からゾウまで基本は共通という授業が本当に面白くて、分子生物学にのめり込んだのです。
中村
分子生物学は大腸菌とゾウは同じという基本を発見するという大きな仕事をしましたが、そこに注目するあまり、最初は共通性というところだけを語っていたのです。ゲノムが登場して「複雑で多様で例外だらけ」を前提に共通性を語るという新しい見方が出た、本当に面白い時でしたね。
冨田
僕が苦手だった高校の生物の授業は、わかっていることだけが書かれた教科書を開いて、例えば、複雑な細胞の姿を見せて、これは何だ、これは何だと説明し、生徒はそれを丸ごと憶えるというものでしたから、その違いに驚きましたね。
中村
分子生物学で変わったのですね。“ Introduction to Modern Biology ” の “ Modern ” の意味はそこですね。
冨田
その通りだと思います。遺伝暗号表(註2)には驚愕しました。3文字のコドンというところもコンピュータのアセンブラ言語(註3)にそっくりで。
中村
その言語で、「複雑、多様」でしかも「例外だらけ」とまで言えるものを生み出すところが面白いですね。それにしても冨田さんは最初に生きものの本質をつかんだよい先生に巡り逢えて幸運でしたね。
冨田
そういう眼で、生物学を見渡すとものすごく面白い。こんなに面白い学問なのに、どうして高校や中学ではつまらない教え方をするんだろうと思いましたよ。
中村
いまだに、その面白さをきちんとは伝えられていない気がします。学校ではわからないことをなかなか語りませんから。
冨田
生物学の面白いところは、やっぱり、わからないことだらけだということ。あるいは、うまくできすぎているというところですよね。例えば、今、生きている多様な生物がどのように進化して今の姿になったのかまだわかっていないし、生命の起源なんてまったくわかっていませんよね。そこを「つかみ」に授業をやれば大部分の生徒は面白がって乗ってくるんじゃないでしょうか。
中村
そうですね。ある部分はうまくできすぎている。そのくせ例外だらけという、両面あるところが生命現象の本質ですからそれをうまく伝えるようにすればいいんですよね。

(註2) 遺伝暗号表
【genetic code table】
メッセンジャーRNAの塩基配列とタンパク質のアミノ酸配列の対応を遺伝暗号といい、コドンと呼ばれるメッセンジャーRNA上の連続した三塩基(トリプレット)がアミノ酸一つを規定する。遺伝暗号表はその対応関係を示す。
(註3) アセンブラ言語
【assembly language】
コンピュータを動作させる機械語は、個々のCPUの内部構造に依存し、人間には理解しづらい数値配列である。そこで機械語の意味を人間が扱いやすい記号や単語に対応させた命令語で記述できるように開発されたプログラム用言語。
3.生物学としての情報科学を
中村
冨田さんは、とてもよい形で生物学にお入りになったと思います。でも、その先、オーソドックスな生物学に進むのなら、発生学でも進化学でも、決まった道が用意されているわけですけれど、生物学をコンピュータとつなげようと言うのですから、そんな道はどこにもありませんでしたでしょ。情報科学と分子生物学をつないでいくところはどのように考えていらしたのですか。
冨田
当時バイオインフォマティクスの研究者のほとんどは、生物学者のためのコンピュータツールの作成に徹していましたが、僕は生物学をやりたくてこの研究を始めたのです。だから小さな発見でもいいから、情報科学にできることで、生物学として意味のある知見を見出すというとことにこだわってきました。
中村
最初はどこから始められたのですか。
冨田
僕が初めて生物学として書いた論文は、遺伝子のエキソンに関する考察でした。その当時、エキソンとイントロン(註4)のデータが3,000件ほど公開されていたので、コンピュータでエキソンの長さを網羅的に調べたところ、3の倍数であることが有意に多かったのです。エキソンの長さを、単純に3の倍数か、3の倍数プラス1か、3の倍数プラス2かの3通りに分けてみた結果です。エキソンシャッフリング(註5)が起きた時に有利な3の倍数のエキソンが進化的に淘汰されずに残ったのではないかと考えました。その論文は、Molecular biology and evolutionに掲載されました。
中村
なるほど。データベースの情報を活用して、そこから新たに知見を見出されたわけですね。
冨田
ええ。でもこのように他の研究者のデータを扱った情報科学の仕事は、なかなか生物学として評価してもらえません。「それは生物学ではない。なぜなら冨田さんは生物学者ではなくコンピュータ屋だからだ」とよく言われましたよ。
中村
それはひどい。それでは新しい分野は生まれないじゃありませんか。でもそういう反応は確かにありますね。
冨田
 そもそも生物学者の定義は、生物学で学位を取得した人だったのです。それなら僕も生物学で博士号を取ってやろうと決心して、自分は教員だけれども履修したい旨を大学に申し出たわけです。慶應医学部にも分子生物学の教室があるので、そこでアメリカで学んだ生物学の続きをやりたいと思っただけのことなのです。
そもそも生物学者の定義は、生物学で学位を取得した人だったのです。それなら僕も生物学で博士号を取ってやろうと決心して、自分は教員だけれども履修したい旨を大学に申し出たわけです。慶應医学部にも分子生物学の教室があるので、そこでアメリカで学んだ生物学の続きをやりたいと思っただけのことなのです。
ところが慶應大学には教員が履修する制度はないので、単位を取得するなら正式な学生になるしかない、と言われました。
中村
入学試験を受けなさいと(笑)。
冨田
ええ。何とか合格して授業料も4年間払って(笑)。1998年にめでたく分子生物学で博士号をいただきました。その博士論文が先ほどのエキソンの話です。当時、指導教授でお世話になった清水信義先生(註6)が、エキソントラッピング(註7)という現象に関心をお持ちだったのでそのテーマを選びました。研究室では、一生懸命実験している人たちと、一緒に過ごしました。情報科学とは異質の文化に身を置いた経験は僕の大きな財産です。おかげさまで博士号をいただくことになり、学位授与式では、僕の研究室で大学院を修了した大学院生たちと一緒に記念写真を撮りましたよ(笑)。
(註4) エクソンとイントロン
【exon / intron】
真核生物ゲノムの遺伝子は、タンパク質をつくる情報をもつエクソン領域に、情報を持たないイントロンと呼ばれるDNA配列が挿入され分断している場合が多い。
(註5) エクソンシャッフリング
【exon shuffling】
別々のタンパク質の機能ドメインをつくるエクソンがイントロン部分で組み換わり、新たな遺伝子を生じること。
(註6) 清水信義
【しみず・のぶよし】
1941年生まれ。慶應義塾大学名誉教授。専門分野はゲノム科学、遺伝子医学。国際ヒトゲノムプロジェクトで21番、22番染色体の解読に大きく貢献した。
(註7) エキソントラッピング
【exon trapping】
エクソンを手掛かりに、DNAの塩基配列から遺伝子座の決定や病気の原因遺伝子の探索などを行う場合に用いる実験的な解析手法。
4.粛々と生きる仮想の細胞
冨田
1995年にマイコプラズマ(註8)の全ゲノムが発表されました。全部で約58万文字で、30億文字のヒトに比べたら小さな数ですが、一つの生物のゲノムが解読された最初のデータでした。しかもインターネットで自由にダウンロードできるというので、「これを元にマイコプラズマを再構築しないか」って学生たちとお酒飲みながら盛り上がったのです。ゲノムに480個ある遺伝子のうち約半数は機能未知でしたが、それぞれの遺伝子の役割を推測しながら全体像を皆で作ろうと言って、一時期、本気で取り組みました。でもさすがに機能未知遺伝子が多すぎたので少し方針を変えることにしたのです。
マイコプラズマにはこだわらず、遺伝子480個の中から、僕らが見て、絶対に必要だと思える遺伝子をかき集めて、最低限の機能で生きられる仮想の細胞を再構築するという目標にしたのです。それがE-CELLプロジェクトの始まりでした。できあがった仮想の細胞の遺伝子は128個でしたが、tRNA遺伝子を除いた機能タンパク質遺伝子数はわずか100未満。たったそれだけの数で粛々と自己を維持して生き続ける。細胞分裂はしませんが、時間経過と共にタンパク質が自然分解するようになっているので、常にタンパク質を作り続けないと死んでしまいます。タンパク質を合成するためにはエネルギーのATPが必要ですが、細胞外からグルコースを取り込み、解糖系でATPを作ります。つまりグルコースを与えておくと、タンパク質を作ってそれがまた別のタンパク質を作ってと、代謝がまわって粛々と生き続けます。これを1999年に発表しました。
中村
 表現としても魅力的な新しい試みでしたので、季刊生命誌(註9)でも取り上げさせていただきましたね。研究成果をどのように表現するかと考えていくところも大切で、そこにも研究の本質があると思います。
表現としても魅力的な新しい試みでしたので、季刊生命誌(註9)でも取り上げさせていただきましたね。研究成果をどのように表現するかと考えていくところも大切で、そこにも研究の本質があると思います。
冨田
どう見せるかと形を考えることも重要です。E-CELLが完成した時、それを情報科学の分野で発表すれば、皆が評価してくれることはわかっていました。しかし、今、僕たちがやろうとしていることは生命科学なのだということを示したくて、あえて分子生物学会でポスター発表しました。想像がつくと思いますが、さんざんな事を言われましたよ(笑)。
中村
本当に新しい仕事ってなかなかわかってもらえませんね。
冨田
中村先生のように、「うーん、私はコンピュータが苦手でよくわからないけれど、こういう仕事が必要になる日はきっと来るだろうな」と言ってくれる方はごくわずかで、ほとんどの生物学者は批判的でした。まず、「これ、実験やったの?」と聞かれ、「やってません」と答えると、「それは分子生物学ではない」って。「そもそも他人のデータだけで考察するなんてどうなの?」とか。僕は何を言われても、「これからの新しい生物学は必ずこうなる」と強い信念があったので、気持ちが揺らぐことは全くありませんでしたが、学生は言われるとかなり動揺していましたね。泣きだす女子学生もいました。だから学会の後は、毎回、学生と飲みに行って「世の中を変えるようなブレイクスルーは、必ず批判されることから始まるんだ」と言って励ます。そこがこの研究で一番苦労したところです。
中村
その頃、泣きながらも面白いからやってみようという学生さんは何人くらいいたのですか。
冨田
このキャンパスは学部生から研究に関わります。そのうち大学院まで進んで、がっちり論文読んで論文書こうという若い人たちが30人くらいはいましたね。今は100人くらい。それだけ大勢の学生を抱えて、一体どうやって指導しているのですかとよく聞かれますが、実は、慶應義塾のモットーにある「半学半教」の精神で、学生同士でうまく教え合うシステムを構築しているのです。皆、後輩と一緒に研究しなさいと言うと、当然、先輩が指導的立場になって、先輩にお世話になった後輩は、自分が先輩になった時に必ずそれをやる。そういう伝統が今も生きているのです。それがうまくまわってE-CELLをやっている学生は本当に好きでやっていますよ。

(註8) マイコプラズマ
【Mycoplasma】
細胞壁をもたない小型の真正細菌。真核生物細胞内に寄生し、多くは病原性を示す。
(註9)
5.方法論は試行錯誤から
中村
今や情報の時代と言われ、生命科学も大量のデータから重要な情報を引き出す時ですが、本格的にコンピュータを生かした研究はまだまだ少ないですね。
冨田
今バイオインフォマティクスの研究室は数多く存在しますが、軸足が情報科学にある限りは、その分野の専門誌に論文を何本出したかで研究の評価が決まるので、「このアルゴリズム(註10)の新規性はどこですか」という類の質問に答えられなくてはなりません。でもそこはシステム生物学として重要な点ではありませんね。やはり既存の分野に軸足を置いたまま研究を続けている限り新しい発想を出すことは難しいでしょうね。
この分野はまだ移民一世の時代なので、本当の意味でのシステム生物学を実践できている研究室は世界でもまだごくわずかです。でも10年後、例えば、僕の研究室のように特殊な環境で経験を積んだ卒業生が、次世代を育成してシステム生物学二世、三世の時代になれば、その時、面白い人材がどっと出てくると期待しています。
中村
なるほど。システム生物学が成熟するまであと10年ですか。10年は短いとも言えますね。あっという間。
でも生命科学の共有財産としてすでに大量のデータが公表されていますから、生命現象の全体像を考えて、データのもつ意味を探し出すという展開をもっと進めて欲しいという気持ちは強いですね。それが私のシステム生物学への期待なのですけれど。
冨田
僕らが構築したE-Cellのようなシミュレーションが生物学にどのように貢献するかということですが、ある複雑な仮説やモデルに矛盾がないということを、実際に動かしてみて証明することができます。自分の提唱する仮説に矛盾がなくデータと首尾一貫していることを示すことはこれからの生物学にとってとても重要なことになると思います。
中村
それに加えて、コンピュータに何かを予測して欲しいという期待もありますね。
冨田
 その通りです。ある細胞で特定の条件が変わった時に、その細胞がどのように振舞うかを予測して欲しい。コンピュータで予測してくれたらそれを実験で確かめて、予測した通りの結果が出れば素晴らしいという展開を皆さんが期待する。でも実はそこが一番難しい。コンピュータで生物学的に興味ある知見を出すというところは体系立った方法論がまだ確立していないのです。
その通りです。ある細胞で特定の条件が変わった時に、その細胞がどのように振舞うかを予測して欲しい。コンピュータで予測してくれたらそれを実験で確かめて、予測した通りの結果が出れば素晴らしいという展開を皆さんが期待する。でも実はそこが一番難しい。コンピュータで生物学的に興味ある知見を出すというところは体系立った方法論がまだ確立していないのです。
中村
私は実験生物学の苦労はわかるのです。仮説を立て、結果を予測して、実験して、うまくいかなかったらまた条件を変えてみてという大変さは想像できます。でもコンピュータで生命現象に取り組む時の大変さは経験がないので具体的に想像できないものですから、もしかしたら過剰な期待をしているのかもしれませんね。コンピュータ側から生物学的な予測までもっていく時の一番のご苦労って、どういうところにあるのですか。
冨田
最初に、まずシミュレーションモデルを作りますが、これもプログラムを精査して期待通りに動くように作るのは、それなりに大変な力作業です。また、元となるデータには必ず誤りが含まれているものなので、その前提でモデルを組む必要があります。
中村
なるほど。
冨田
 次は、そのモデルで考察するためのシミュレーションを設計します。あるパラメータを倍に増やした場合、5倍、10倍にした場合、1/2、1/10に減らした場合など何通りかの設定を変えてシミュレートするわけですが、多くのパラメータについて全通りの組み合わせをやるためには、例えば、一万通りのパラメータを変えたシミュレーションを一晩中行い、その結果、顕著に振る舞いが変化した場合だけを抽出するというプログラムを予め仕込んでおく。ここまでの大変さは馬力の問題です。一番の苦労はと言うと、シミュレーションの結果、顕著な振る舞いをした時に、それをどう解釈するかです。 あるパラメータはほんの少し値を変えただけで大きく現象が変化する非常に繊細なパラメータだということがわかったり、あるパラメータの変化が予想外の振る舞いを引き起こすことがわかったりします。そこで、パラメータと現象とを手掛かりに過去の知見や論文を探し、その現象を解釈して説得力ある仮説を組み立てていくところが最も難しい。でもここが生物学として仕事が膨む最も面白いところでもあります。
次は、そのモデルで考察するためのシミュレーションを設計します。あるパラメータを倍に増やした場合、5倍、10倍にした場合、1/2、1/10に減らした場合など何通りかの設定を変えてシミュレートするわけですが、多くのパラメータについて全通りの組み合わせをやるためには、例えば、一万通りのパラメータを変えたシミュレーションを一晩中行い、その結果、顕著に振る舞いが変化した場合だけを抽出するというプログラムを予め仕込んでおく。ここまでの大変さは馬力の問題です。一番の苦労はと言うと、シミュレーションの結果、顕著な振る舞いをした時に、それをどう解釈するかです。 あるパラメータはほんの少し値を変えただけで大きく現象が変化する非常に繊細なパラメータだということがわかったり、あるパラメータの変化が予想外の振る舞いを引き起こすことがわかったりします。そこで、パラメータと現象とを手掛かりに過去の知見や論文を探し、その現象を解釈して説得力ある仮説を組み立てていくところが最も難しい。でもここが生物学として仕事が膨む最も面白いところでもあります。
中村
コンピュータの得意な力作業と自分で考えることの組み合わせですね。なるほど。伺っていてそれこそ今の時代で一番面白いところではないかと思えるので、そういう研究がもっとあって欲しいですね。大量のデータを一晩で操作できるなんて実験生物学では絶対にできませんから。
冨田
今、サラッと言っちゃいましたので、簡単に思われるかもしれませんが、そこは試行錯誤に満ちていて、まだまだ未知の分野なのです。
中村
わかりました。でも、だからこそ情報科学としても挑戦しがいのある面白いところじゃないのかしら。
冨田
ええ。僕はそう思うわけです。
中村
どうしてそういう方向へ行く方が少ないのかなあ。もっと広げて下さい。
冨田
コンピュータもPCR装置(註11)やシークエンサー(註12)と同じ、一つの道具に過ぎません。要するに、知りたいのは生命現象であって、それを知るためには何だってやります、何だって使いますというマインドが必要かと。
中村
それには、そもそもの興味が生命科学にある人が情報科学を勉強しなければいけないのかもしれませんね。これからそういう人を育てていかなくてはいけませんね。大量に出てくるデータを無駄にしてはもったいないので。

(註10) アルゴリズム
【algorism】
コンピュータで演算手続きを指示する規則。算法。
(註11) PCR装置
【polymerase chain reaction machine】
DNAを増幅するポリメラーゼ連鎖反応法を用いた装置。微量の試料から特定のDNA断片を選択的に増幅する。
(註12) シークエンサー
【sequencer】
DNAの塩基配列を解析する装置。
6.どこをサボるかが本質
中村
生命誌研究館は京都と大阪の間の高槻にあります。本郷や三田の人には、「それ一体どこ?」と聞かれるような、中心から外れた場所です。同じことを東京でやっていたら違う形もあり得ただろうとは思いますが、私は拠点が地方にあることのメリットはあると感じています。冨田さんの研究所も鶴岡という地域に根ざして発展的にやっていらっしゃる。これは日本の学問の在り様へのあるメッセージですよね。
冨田
鶴岡に先端生命科学研究所を設立したのは2001年ですから、もう10年になります。オックスフォードもケンブリッジもハーバードもみな田舎町にありますよ。学問や研究を大都会でやる必要は全くないのに、日本は大学も研究所も都市に集中し過ぎていますね。むしろ自然に囲まれたところでリラックスして考えるほうが発想も湧いてきます。創造的な仕事をするのに、みんなと同じ場所にいないとどこか不安だというのは、中央から外れると主流から落ちこぼれたように感じる日本人のなさけないメンタリティで、その意識を変えなくてはいけませんね。
中村
変に周りを意識しないで、本当に何か面白いことを始められる場所は、むしろ都会から外れた地域だということも言えますよね。
冨田
人間誰しも皆に褒められたいという心理はあるので、常に周りに「優等生」が大勢いるような場所では、やはり一年半程ですぐ成果が出て論文になるという研究をくり返すようになりますよ。ブレイクスルーを出してやろうという気概は生まれません。
僕は鶴岡の研究所を、真に独創的なオンリーワンの環境だと自負しています。そのひとつが世界に誇れるメタボロームの一大工場で、海外からも、メタボローム研究の先行事例を見学したいという人々が数多く訪れます。ある部屋には、高価な質量分析計がずらっと何十台も並べてあり、また奥の壁一面鏡張りにしてあるので、皆が腰を抜かします(笑)。
中村
倍に見えるのね(笑)。ずるいなあ。
冨田
 もちろん、「あれは鏡です」と言いますが、僕は、そこにあえてハッタリの意味を込めているのです。ハッタリだとわかっていても強い印象を与えるので、これと同じことやっても勝てないから違うことをやろうかなと思わせる bruff効果を狙っています。中村先生も是非一度見に来て下さい。
もちろん、「あれは鏡です」と言いますが、僕は、そこにあえてハッタリの意味を込めているのです。ハッタリだとわかっていても強い印象を与えるので、これと同じことやっても勝てないから違うことをやろうかなと思わせる bruff効果を狙っています。中村先生も是非一度見に来て下さい。
中村
そこまで行っていない始まりの時に伺いましたよね。鶴岡でのメタボローム研究の中で、今、どんなところが面白くなっているのか、少し教えて下さい。
冨田
もともとメタボロームを始めたきっかけはE-CELLでした。15年前、細胞のシミュレーションモデルをもっと実物に近づけたいと思っても、世の中に定量的なデータがほとんどなかったのです。分子生物学の教科書に書いてあるのは定性的な情報ばかり。例えば、あるタンパク質が別のタンパク質と結合して、それが何々を抑制すると書いてあるけれど、タンパク質がどれくらいの親和性で結合して、どれくらい抑制するのか一切書いてないのです。
中村
なるほど。確かにそうですね。
冨田
定量的情報がないとシミュレーションは一切できません。それなら自分たちでデータを取得しようと、分析化学のチームを作り世界に先駆けてメタボロームを始めたわけです。当時はメタボロームという言葉すらありませんでしたが、細胞内の数百、数千の代謝物質を一斉に測定できる技術を開発し、2002年に特許を取りました。そこで、一点集中で相当な予算を充当し、マシンも増やし、技術も開発し、どこの研究所にも、どこの国にも負けない技術にしようと言ってがんばっているのです。幸い、これは汎用技術なので、農業、医療、微生物へと応用できて、学生のテーマとしても面白いのです。彼らもとてもがんばっていて、幅広く展開すると今まで見えなかったものが見えてきます。
中村
 わかりました。冨田さんの研究所では、本当に多彩な分野のお仕事を手がけていらっしゃいますが、それはコアの技術に汎用性があるからなのですね。それをすごいなあと思う一方で、やはり生物学としての研究の面白さから言うと、次の展開として、より本質的な細胞のモデルへ近づくという方向へも踏み込んで欲しい。メタボロームで取得した定量的データを活用して、例えばE-CELLの時に盛り込めなかった細胞分裂などの現象も扱って、もう一歩深めたシミュレーションには挑戦なさらないのですか。
わかりました。冨田さんの研究所では、本当に多彩な分野のお仕事を手がけていらっしゃいますが、それはコアの技術に汎用性があるからなのですね。それをすごいなあと思う一方で、やはり生物学としての研究の面白さから言うと、次の展開として、より本質的な細胞のモデルへ近づくという方向へも踏み込んで欲しい。メタボロームで取得した定量的データを活用して、例えばE-CELLの時に盛り込めなかった細胞分裂などの現象も扱って、もう一歩深めたシミュレーションには挑戦なさらないのですか。
冨田
実はこの夏にスタンフォードの研究グループが細胞分裂するマイコプラズマのシミュレーションモデルを発表しています。でもその仕事はE-CELLの延長だと思ったのです。僕らは1999年に細胞全体でシミュレートすることが可能だということを最初に示せたと思います。彼らは、その後13年かけて遺伝子数を128から570に増やし、細胞が分裂できるようにしたわけです。いい論文にはなったようですがモデルが示す可能性は変わらないでしょう。モデルはどこまでも本物に近づけることができますから、この終わらない仕事をどこまでやるのか。その時、問われるのは、それをやることで何がわかるのかです。何かを知りたい時に必ずしも細胞のすべてを正確にシミュレートする必要はありません。本質と関係ないところは思いきって抽象化して、計算量もうんと小さくしてサボることが重要です。そのうえで重要なところは必要なだけ細かくデータを盛り込んでシミュレートして全体像を見るというやり方が本質だと思います。
中村
なるほど。それでよくわかりました。本質がどこにあるかを見抜いて割り切っている。
冨田
やはりE-CELLも道具なので、今の問われているのは、シミュレーションモデルによって何がわかるのかです。
中村
それでさまざまな具体的現象を見ていくことに意味があると思っているわけなのね。
冨田
ええ。どこを抽象化すればよいのか、どのように抽象化するのかについても多くの試行錯誤があるのです。ですから何が本質なのかを見極める眼力を持たなければなりません。

7.経験から浮かび上がる全体像
中村
今のお話はとても面白いところですので、どんなところに本質を見て、その他をどうやって抽象化していくのか実例で教えて下さいませんか。
冨田
 E-CELLでヒトの赤血球細胞のシミュレーションを行っているチームがあります。G6PD(註13)遺伝子が生まれつき欠損した患者さんは、貧血を起こすという報告がありました。その詳細を調べようと思い、エネルギー代謝に絞って赤血球細胞のモデルをE-CELLで作りました。主要なエネルギー代謝であるペントースリン酸回路(註14)などについては定量的なパラメータを詳細に定義し、赤血球のメタボローム解析で得た中間代謝物の定量的データも盛り込んで可能な限り正確なモデルにしました。シミュレーションでG6PD酵素を欠損させると代謝が変わりますので、その結果と、実際の患者さんの赤血球を調べたデータとを比較して検証を重ねました。
E-CELLでヒトの赤血球細胞のシミュレーションを行っているチームがあります。G6PD(註13)遺伝子が生まれつき欠損した患者さんは、貧血を起こすという報告がありました。その詳細を調べようと思い、エネルギー代謝に絞って赤血球細胞のモデルをE-CELLで作りました。主要なエネルギー代謝であるペントースリン酸回路(註14)などについては定量的なパラメータを詳細に定義し、赤血球のメタボローム解析で得た中間代謝物の定量的データも盛り込んで可能な限り正確なモデルにしました。シミュレーションでG6PD酵素を欠損させると代謝が変わりますので、その結果と、実際の患者さんの赤血球を調べたデータとを比較して検証を重ねました。
このような場合、どこを抽象化するのがよいかという見極めが大事です。通常、シミュレーションのために細胞をモデル化する時には、すべての酵素が満遍なく一様に分布しているというところから始めます。実際の細胞はそうはなっていませんよね。ある酵素は、細胞膜付近に局在していたりするわけです。その局在を正確に再現すべきか否かを判断しなければなりません。その時、今見ようとしている現象に対して、その局在が決定的に影響すると思えば、濃度勾配などのパラメータを入れて考慮します。しかし、関係がないのであれば思いきって一様にして、そこはサボる。
中村
それは生物学の研究成果を見て考えるわけですね。
冨田
はい。どこをサボって、どこを盛り込むかの選択は非常に難しいところです。それがこの研究の本質になるのです。
中村
注目する現象によって、サボっていいところ、サボっちゃいけないところが変わってくるわけですね。そういう知識を積み重ねていけば細胞の全体像が浮かび上がって、複雑で多様で例外だらけという生きものの本質が見えてくるかもしれませんね。
冨田
長期的にはそうですね。それは経験なのです。
中村
 研究って論理が基本には違いないけれど、経験や直感が重要ですね。冨田さんの研究所は応用分野の成果がたくさん出されていて、それがどれも面白いでしょう。確かに応用例は社会の評価は得やすく大事だけれど、基礎のところが見えにくくなってしまいますでしょ。お話を伺って大変よくわかりました。さまざまな応用研究は、基礎研究の試行錯誤の一環としてあるわけですね。
研究って論理が基本には違いないけれど、経験や直感が重要ですね。冨田さんの研究所は応用分野の成果がたくさん出されていて、それがどれも面白いでしょう。確かに応用例は社会の評価は得やすく大事だけれど、基礎のところが見えにくくなってしまいますでしょ。お話を伺って大変よくわかりました。さまざまな応用研究は、基礎研究の試行錯誤の一環としてあるわけですね。
冨田
地道な基礎研究と社会から評価を得やすい応用研究とどちらも重要です。応用でも成果が出せると社会の評価だけでなく自分たちの士気も上がります。だから両方のバランスが重要なのです。
生命現象におけるDNAやタンパク質の重要さはもちろん変わりませんが、そこにメタボロームで見えてきた細胞内の多様な代謝産物の定量的情報が加わることで、より深く細胞や個体レベルの実態に迫れるようになったと自負しています。
中村
最初に、若い頃人工知能を作るんだという熱い思いを胸に米国に渡ったと言われたけれど、今のお仕事を通して、あの頃の夢に少し近づいたという感覚はお持ちですか。
冨田
人工知能の難しさは今も変わっていませんね。僕らはよくジョークで “ It takes 2.5 Einstein ” って言っていました。アインシュタインの相対性理論に匹敵するブレイクスルーが2.5個必要だという意味です。
中村
データ量を増やしてもダメ。新しい考え方が必要ということですね。それもとびきり新しいのが。
冨田
今のやり方をいくら積み上げても届かないでしょうね。脳という臓器も一つの細胞が分裂してできあがっているわけで、そのおおもとのところには必ずその謎が書いてあるはずですよね。僕が生きている間に、脳のしくみまで理解できないかもしれないけれど、細胞だったら理解できるかもしれません。だからまずできることを。
中村
細胞がわかったらすごいですよ。この方向の研究は、まだ道が見えないだけに若い人に飛び込んでもらえる環境をつくらないといけませんね。
冨田
僕の体験でいえば、米国には、どんでもないことでもダメモトやってみようという雰囲気があります。一方、日本人はまじめなので、確実に論文になる主流な仕事をするのが良いとされる。この辺の考え方を変える必要があると思います。
中村
日本の科学にとって大事なところですね。

植物細胞のシミュレーション「e-Rice プロジェクト」のための代謝マップの前で。冨田研究室では学生たちが中心となり、この他にも「e-大腸菌プロジェクト」「心筋細胞プロジェクト」「e-neuron プロジェクト」などの形でE-CELLプロジェクトを展開している。
写真:大西成明
対談を終えて
中村桂子
BRHを始める時、細胞や個体の全体像を知るには、分子のはたらきの全体を捉えるコンピュータの力が必要だと思いました。情報専門家で生物学に眼を向け、大きな可能性をもつ若手と映ったお一人が冨田さんでした。研究室を訪れコンピュータ内の細胞を見せていただき、面白いと思うと同時に正直ちょっと物足りなさを感じました。しかし、その後の実験も含めた精力的な活動で生命現象に具体的に迫る研究はみごとです。生命誌として教えていただきたいこと山ほどです。(中村桂子)
富田 勝
生命の本質をつかむ
人間という知的システムの思考をコンピュータで再現したい。私はアメリカで人工知能の研究に邁進していました。しかし人間の知能のしくみがあまりに難解で研究がなかなか前に進まず呆然としていた頃、ヒトゲノムという言葉に出会いました。ヒトの設計図はわずか30億文字で構成されていて、その中に、脳や心臓のつくり方や動き方がすべて詳細に記載されているというのです。当時32歳だった私はそのことに衝撃を受け、そして「自分が生涯かけて取り組むべきは生命科学だ」と確信したのでした。中村桂子先生とはその頃からずっと私の良き理解者としてアドバイスを頂いてきました。久しぶりにじっくりお話できてとても楽しかったです。

冨田 勝(とみた まさる)
1957年東京生まれ。慶應義塾大学工学部数理工学科卒業、カーネギーメロン大学コンピュータ科学部大学院修了後、同大学准教授、同大学自動翻訳研究所副所長を務める。1990年より慶應義塾大学で教鞭を執り、後に同大学環境情報学部教授、同学部長を歴任。2001年より同大学先端生命科学研究所(IAB)所長。Ph.D.(情報科学)、工学博士(電気工学)、医学博士(分子生物学)。